AI News
Bridging Modalities with VisionLLaMA: A Unified Architecture for Vision Tasks
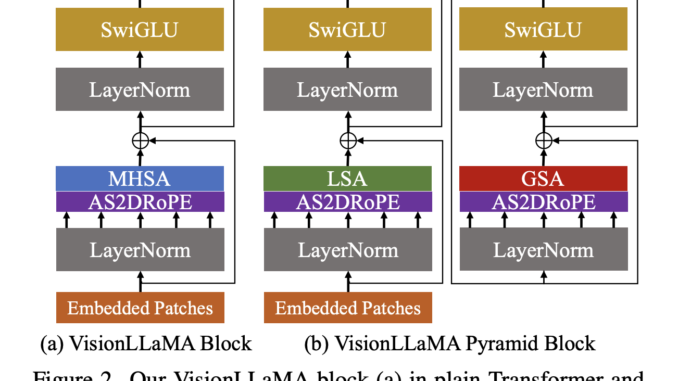
[ad_1] Large language models, predominantly based on transformer architectures, have reshaped natural language processing. The LLaMA family of models has emerged as a prominent example. However, a fundamental question arises: can the same transformer architecture […]