



[ad_1]
In AI, a particular interest has arisen around the capabilities of large language models (LLMs). Traditionally utilized for tasks involving natural language processing, these models are now being explored for their potential in computational tasks such as regression analysis. This shift reflects a broader trend towards versatile, multi-functional AI systems that handle various complex tasks.
A significant challenge in AI research is developing models that adapt to new tasks with minimal additional input. The focus is on enabling these systems to apply their extensive pre-training to new challenges without requiring task-specific training. This issue is particularly pertinent in regression tasks, where models typically require substantial retraining with new datasets to perform effectively.
In traditional settings, regression analysis is predominantly managed through supervised learning techniques. Methods like Random Forest, Support Vector Machines, and Gradient Boosting are standard, but they necessitate extensive training data and often involve complex tuning of parameters to achieve high accuracy. These methods, although robust, lack the flexibility to swiftly adapt to new or evolving data scenarios without comprehensive retraining.
Researchers from the University of Arizona and Technical University of Cluj-Napoca using pre-trained LLMs such as GPT-4 and Claude 3 have introduced a groundbreaking approach that utilizes in-context learning. This technique leverages the models’ ability to generate predictions based on examples provided directly in their operational context, thus bypassing the need for explicit retraining. The research demonstrates that these models can engage in both linear and non-linear regression tasks by merely processing input-output pairs presented as part of their input stream.

The methodology employs in-context learning, where LLMs are prompted with specific examples of regression tasks and extrapolate from them to solve new problems. For instance, Claude 3 was tested against traditional methods on a synthetic dataset designed to simulate complex regression scenarios. Claude 3 performed on par with or even surpassed established regression techniques without parameter updates or additional training. Claude 3 showed a mean absolute error (MAE) lower than Gradient Boosting on tasks such as predicting outcomes from the Friedman #2 dataset, a highly non-linear benchmark.
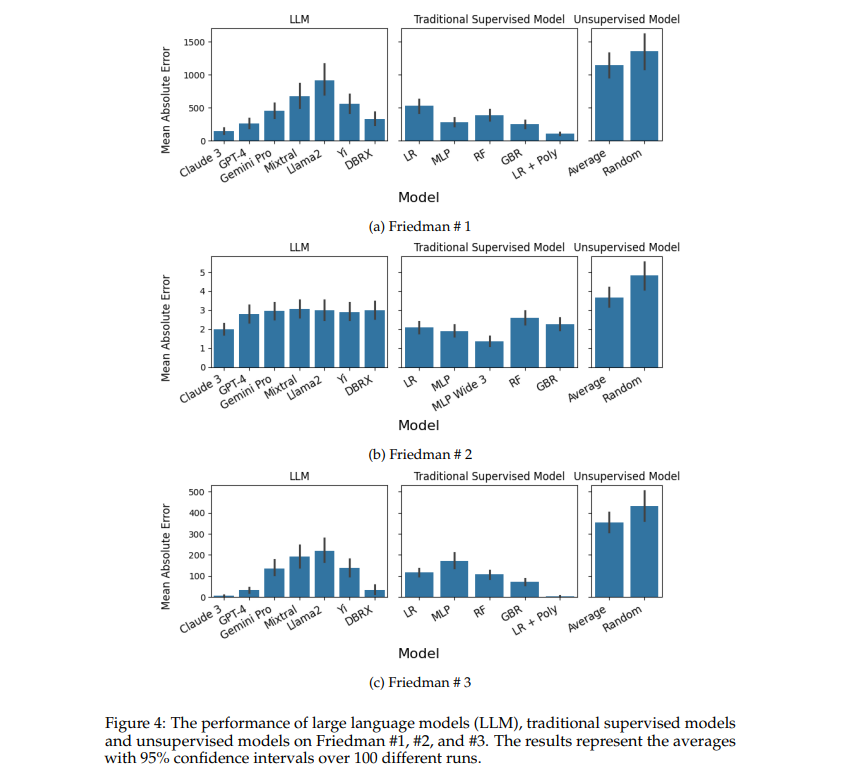
The results across various models and datasets in scenarios where only one variable out of several was informative, Claude 3, and other LLMs like GPT-4 showed superior accuracy, achieving lower error rates than supervised and heuristic-based unsupervised models. For example, in sparse linear regression tasks, where data sparsity typically poses significant challenges to traditional models, LLMs demonstrated exceptional adaptability and accuracy, showcasing an MAE of just 0.14 compared to the nearest traditional method at 0.12.
RESEARCH SNAPSHOT

In conclusion, the study highlights the adaptability and efficiency of LLMs like GPT-4 and Claude 3 in performing regression tasks through in-context learning without additional training. These models successfully applied learned patterns to new problems, demonstrating their capability to handle complex regression scenarios with precision that matches or exceeds that of traditional supervised methods. This breakthrough suggests that LLMs serve a broader range of applications, offering a flexible and efficient alternative to models that require extensive retraining. The findings point towards a shift in utilizing AI for data-driven tasks, enhancing the utility and scalability of LLMs across various domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
[ad_2]
Source link
Be the first to comment